- Home /
- NOC 24/7 /
- NOC Automation Services and Operational Playbooks
NOC Automation Services and Operational Playbooks
Manual IT operations can slow response times, introduce errors, and cause inconsistencies in how incidents are managed. At IAMOPS, we help tech companies eliminate these bottlenecks through robust NOC automation services and operational playbooks that improve infrastructure reliability, accelerate resolution, and reduce manual intervention. We specialize in automating synthetic testing, incident response, and system operations by integrating predefined workflows into your monitoring platforms, alerting systems, and CI/CD pipelines.
Our approach enables self-healing infrastructure, proactive detection, and automated alerts—ensuring minimal downtime and standardized incident handling. Whether you’re a fast-scaling SaaS company, a FinTech platform, or an enterprise managing hybrid environments, IAMOPS delivers custom NOC automation and incident response playbooks tailored to your infrastructure, compliance needs, and growth roadmap. By reducing repetitive tasks and enabling 24/7 operational efficiency, we empower your team to focus on building, not firefighting.
With a proven track record in 24/7 managed NOC services, an automation-first approach, and custom-built SLAs-driven workflows, IAMOPS ensures consistent results through seamless integration with your existing tools and teams—trusted by high growth companies around the globe.
What IAMOPS Offers
Comprehensive
Automation and Playbook Strategy Design
We start by evaluating your current monitoring, alerting, and incident response workflows to identify inefficiencies and automation opportunities. Our experts design tailored NOC automation workflows and response playbooks that proactively handle incidents, reduce MTTR, and ensure operational consistency across your infrastructure.
Our strategic design services include:
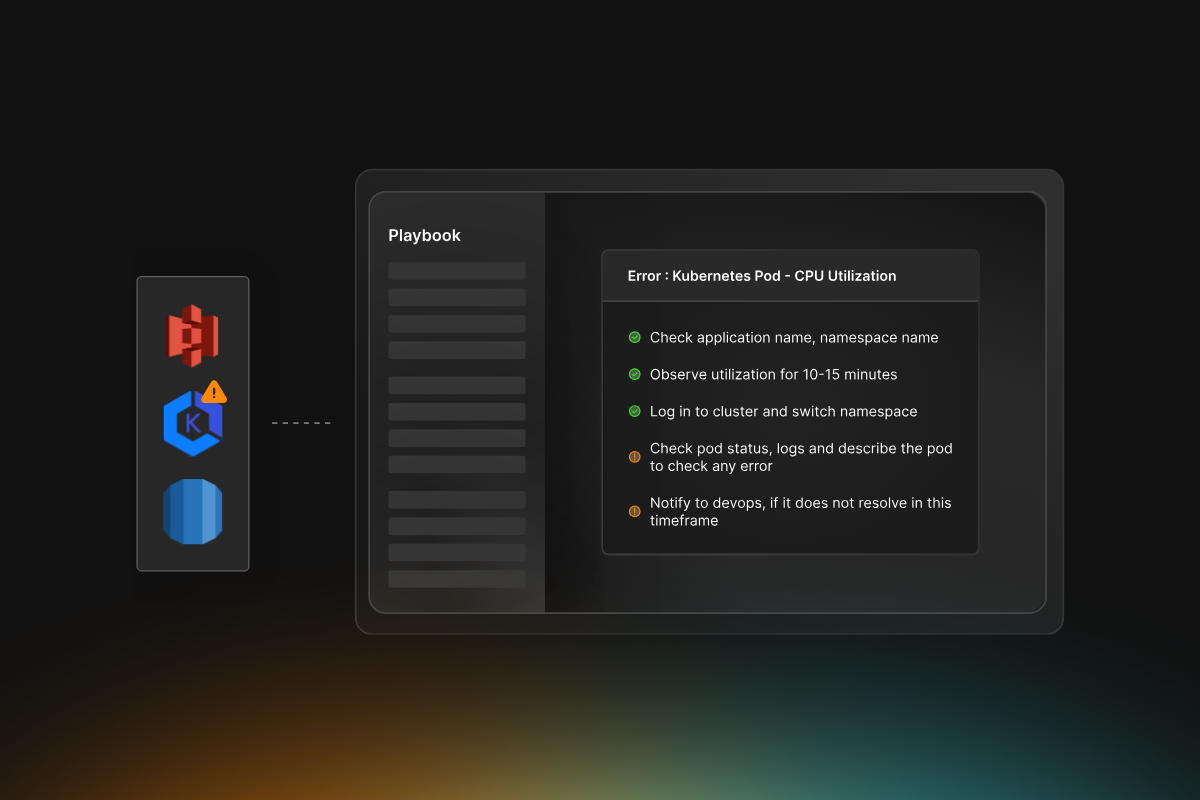
- Identify synthetic testing scenarios (e.g., login failures, checkout disruptions) that require automated responses
- Define incident playbooks for resolving performance issues, security threats, and system failures
- Select automation tools like Datadog Synthetic Monitoring, AWS CloudWatch Synthetics, New Relic, or custom tests using AWS Lambda or Azure Functions
- Design automated workflows to trigger alerts, log incidents, and apply remediation actions based on test results
- Alert classification and severity mapping for targeted responses
- Escalation paths and notification rules
Automation and Playbook
Implementation
Once the strategy is defined, IAMOPS integrates automated solutions that ensure incidents are detected and resolved swiftly, with minimal manual intervention. These playbooks and automations are tightly integrated with your existing DevOps and NOC stack for seamless operation.
What we implement:
- Automate synthetic test execution across geographies and devices to detect UI, API, and performance issues
- Set up self-healing mechanisms that automatically restart failed services or roll back deployments
- Implement automated alerts and workflows in tools like UptimeRobot, ZenDuty, and Slack
- Integrate synthetic test automation with CI/CD pipelines
- Include tools and scripts to be run automatically per incident
- Ensure post-resolution verification and documentation are captured within the playbook
Ongoing
Automation Optimization and Support
We believe NOC automation is not a one-time setup but a continuous evolution. IAMOPS ensures your automation workflows, synthetic tests, and playbooks are regularly updated, optimized, and expanded to handle changing tech environments and reduce operational noise.
Ongoing support and optimization include:
- Continuously update synthetic test scripts based on app workflow changes
- Optimize alert thresholds and logic to reduce false positives
- Expand automation to monitor new metrics like latency, third-party availability, or API health
- Continuously updated SOPs post-incident analysis
- Data-driven improvements in automation logic
- Reduction in repetitive incidents over time and lower MTTR
Toolchain
Integration and Workflow Automation
IAMOPS ensures complete automation across your monitoring and incident response stack by configuring tool integrations, workflows, and resolution scripts that match your infrastructure and SLA goals.
Toolchains we support:
- Monitoring: Datadog, Grafana, Prometheus, CloudWatch
- Alerting: PagerDuty, Zendesk, Slack
- Orchestration & Automation: Ansible, Terraform, custom remediation scripts
Benefits
Faster and More Reliable Incident Detection
Automated synthetic testing continuously monitors application functionality, allowing for immediate detection of failures before they impact users.
Reduced Manual Workload
Automation eliminates the need for manual monitoring and troubleshooting, allowing teams to focus on high-value development and operations tasks.
Proactive Issue Resolution
By integrating automation with incident response workflows, we ensure that critical issues are identified and resolved before they cause disruptions.
Scalable and Adaptive Automation
Our solutions grow with your business, ensuring that monitoring, alerting, and synthetic testing automation evolve with your infrastructure.
Let’s Automate Your NOC
Ready to stop firefighting and start scaling? IAMOPS can help automate your entire NOC and equip your team with powerful playbooks for consistent, reliable, and round-the-clock IT operations.
Book your free NOC automation consultation and discover how we make network operations smarter, faster, and more predictable.
Our success stories






Frequently Asked Questions (FAQ's)
What are NOC automation services?
NOC automation services refer to automating monitoring, alerting, and resolution tasks in a network operations center to reduce manual intervention and speed up incident handling.
What is an incident response playbook?
An incident response playbook is a documented, step-by-step guide that outlines how your NOC team should respond to specific types of incidents—ensuring consistency and speed.
Can IAMOPS customize automation for our environment?
Absolutely. We tailor every script, workflow, and playbook to your tools, infrastructure, and business priorities.
What tools do you support for automation?
We work with industry-standard tools like Prometheus, Datadog, CloudWatch, Opsgenie, PagerDuty, Ansible, and more—integrating them into seamless workflows.
How do playbooks help reduce MTTR?
Playbooks standardize how incidents are handled, reducing decision-making delays and ensuring swift, confident action from your team.
- NOC System Set-up
- NOC Automation Services and Operational Playbooks
- 24/7 Network Monitoring Services
- 24/7 Incident Management Services
- 24/7 Application Support Services

