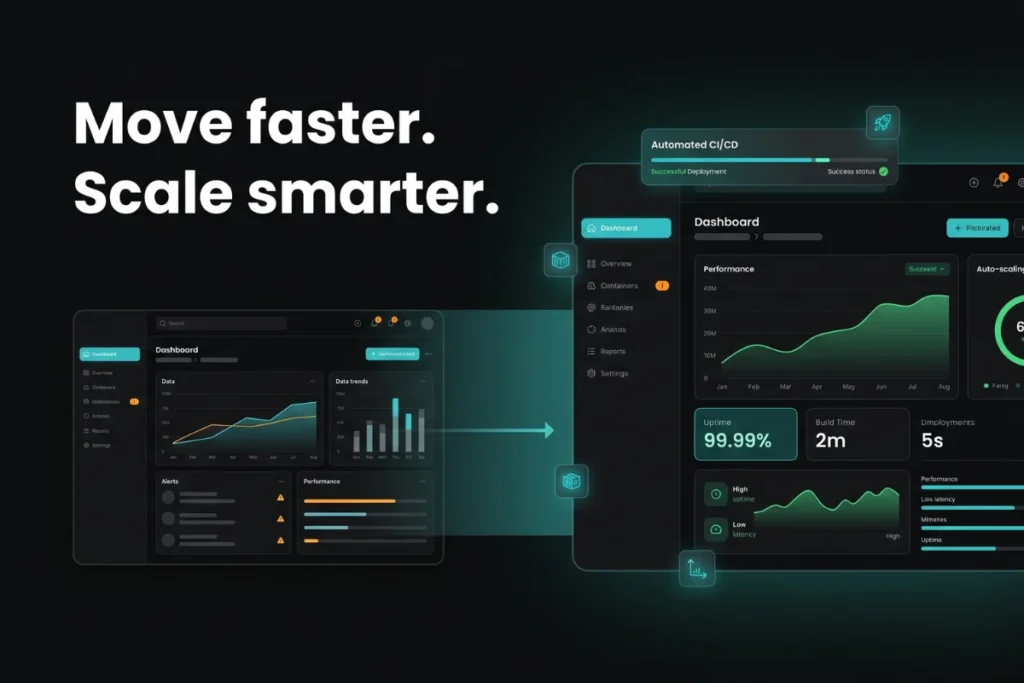
In modern software development, speed and quality must go hand in hand. Businesses want faster releases, but users also expect stable, secure, and reliable applications.…
Modern software teams are expected to release updates quickly, fix bugs faster, and maintain application stability at the same time. Manual build and deployment processes…
Software as a Service, commonly known as SaaS, has changed the way businesses deliver software to customers. Instead of installing applications on individual systems, users…
Modern software applications need to be fast, reliable, scalable, and secure. Businesses are expected to release updates quickly while maintaining performance across different environments. Traditional…
Network Operations Centers, commonly known as NOCs, play a critical role in keeping IT infrastructure, cloud systems, applications, and networks running smoothly. NOC teams monitor…
A production system can be healthy and still fail its SLA. The application may be running. The infrastructure may be stable. Internal services may show…
Incident response systems have become increasingly automated. Monitoring platforms detect anomalies in seconds. AI models correlate events across services. Automated workflows trigger remediation before engineers…
Production incidents rarely appear without warning. Before a service outage, SLA breach, or customer-impacting failure, the system usually sends weak signals: latency starts drifting upward,…
Startups operate in a high-pressure environment where speed, scalability, and cost efficiency determine success. In this competitive landscape, adopting DevOps services for startups is a…
In modern software development, speed and agility are critical, but they should never come at the cost of security. As organizations increasingly rely on third-party…